
在学习B+tree之前,我们需要知道一些知识,比如数据库是需要保存到磁盘上的,那么在了解b加树之前,我们需要了解磁盘是怎样存储的
说先我们应该知道,CPU是无法与磁盘进行直接互动的,因为CPU的读写速度要远远超于磁盘的IO速度,所以他们之间就由内存来作为媒介,而内存与磁盘的交互速度又取决于io速度,那么影响io效率的因素也就会导致磁盘查找效率的快慢。
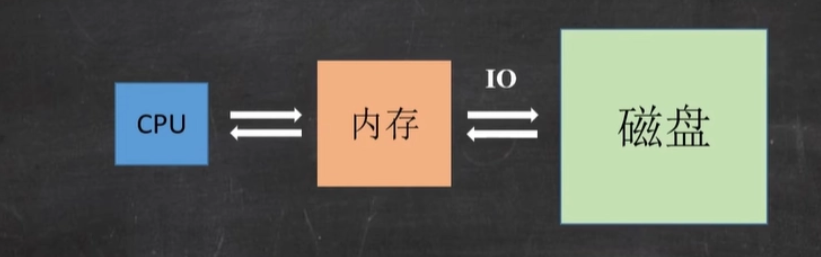
比如数据越大、次数越多读写越慢。
知道了这些前置条件,我们来看磁盘的存储:
磁盘的存储
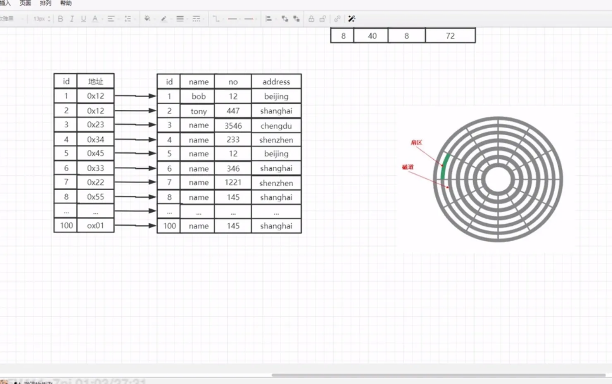
可以看到 我们可以将磁盘分为很多盘片,如果磁头想要读取数据的话,磁头必须要知道是存储到哪个位置的。
那么磁盘是如何定位位置的呢?
是通过磁道来划分的(图中黑色圆圈)每一圈都是一个磁道,因为磁道是圆环,其实还不能定位准确位置。
而在磁盘上,还存在很多竖线,这些数显把磁盘等分为很多部分,通过磁道和扇区的定位,就可以精准得到数据的存储地点了。
而这也是最小的存储单位,512个字节(每个磁区数据存储能力一样)
那举个例子,加入我们现在有800个数据,每个数据在表格里所占的字节是128,那整体所有表格录入到磁盘后想要被完全读取至少需要200次,可以发现,这样的读取速度实在是太慢了。
解决方法就是,我们可以将表格中的元素的主键id复制出来,加入到新的表里,这张新的表格里只有id和地址,而这张表就是——索引表。
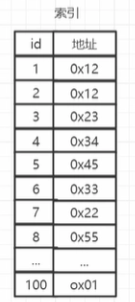
假设现在有800个索引,800*(8+8)=?/512=25次
最坏的情况要找从500次变成最坏找25次,已经很好惹

如果数据大到连索引里的数据算起来都要找很多次后,可以套娃给索引上索引,比如索引8个为一组,假设原索引有800个,二级索引只需要100个
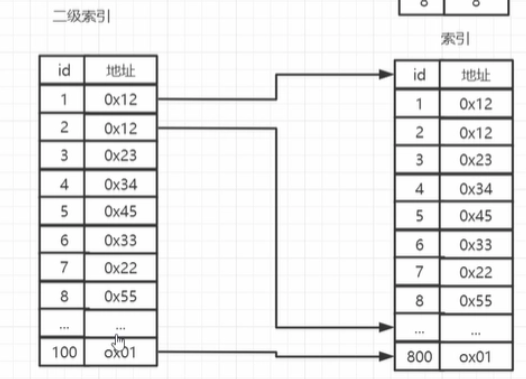
800*16/8=4次
而且其实一个二级索引单位对应的是一整个扇区的字节,所以最多组数其实不止是8个,一个扇区里面可以有512个字节,一个索引有16个字节,那么实际上就可以指向32个索引
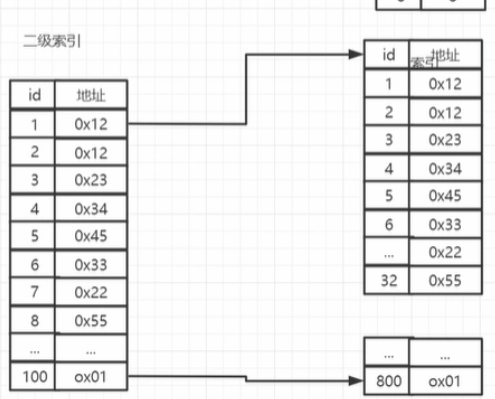
那么索引原来有800个,一组分为32个,800//25==25
所以二级索引其实只需要25个
25*16不满足512个字节,所以其实二次索引只需要一次io就可以读取所有的二级索引,就可以快的定位到索引的位置
二级索引因为已经清楚了区域,只需要再一次io就可以找到目标的具体位置
这样两次就出来了
B树与B+树的区别
这时,我们已经可以得到b树与b+树的区别:
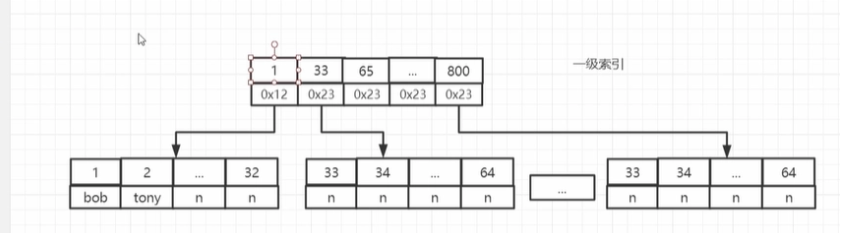
B树:在一级索引中获取主key,只获得所要取的值的地址,而不进行拿取
B+树:在一级索引中获得主key后,根据地址拿出要取的值
同时B+树还会把最底层的数据用链表将他们连接起来,并且B+树是可以有高度的,一级索引上面还可以有二级索引、三级索引等等
到这里我们已经充分了解了B+树的工作原理了
B+tree的结构图
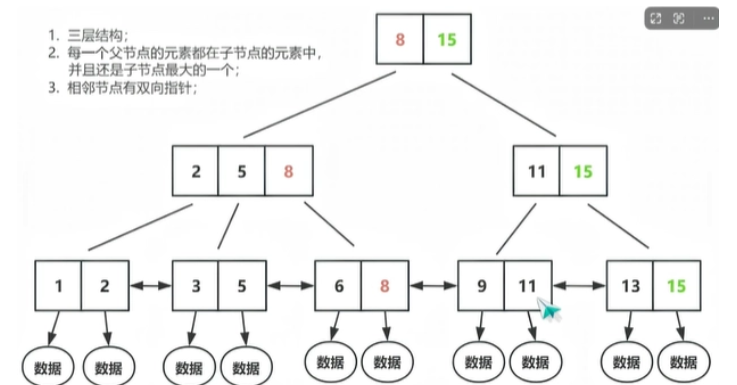
1.三层结构
2.每一个父节点的元素都在子节点的元素中,并且还是子结点中最大的一个
3.相邻节点都有双向指针
4.只有第三层的节点存储了数据
5.有序
了解了他的原理和结构,我们来进阶想几个问题,为什么MySql不使用B树而是B+树呢?
MySQL为什么使用B+树而不是B树?
想要了解这个问题,我们必须也弄明白B树的工作原理
既然都讲到b树和b+树在sql的应用了,我们顺带也是来说说其他书为什么不能被用于MySQL:
首先,二叉树:
因为二叉树是没有序的,如果想要索引,其实还是要逐个遍历的
二叉排序树:
二叉排序树的特点:左右子树不为空时,左子结点的值<根结点的值;右子结点的值>根结点的值
但如果应用在数据库时,插入数的顺序是从小到大输入的,那么树的形态就会变成:
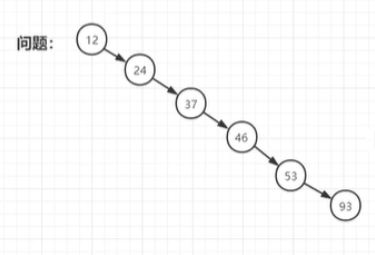
这样查找效率从logn又变为n了,又变为线性查询了,实际应用时局限性太大了
那为了解决这个问题,二叉平衡树登场了:
也就是当二叉排序树遇到以上情况时,实时旋转以解决问题,使得插入数据的时候就保持二叉排序树的平衡(还有序)
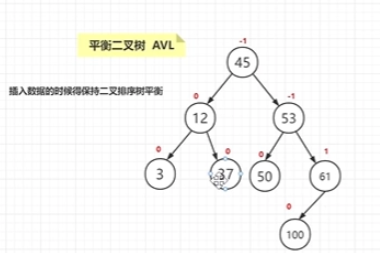
但他还是有问题,在插入旋转的过程中,也是需要更多的算法算力去支持的,也就是说,实际上,二叉平衡树是在用插入的成本来弥补查询的效率。
只有在查询请求远远大于插入操作情况才实用,一旦不大于,开销就太大了。
红黑树登场:
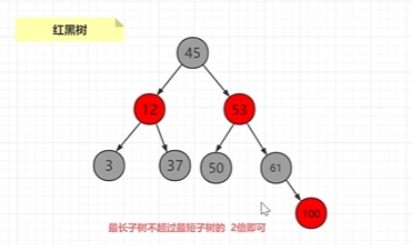
我们这里不详细展开红黑树的讨论,反正 他解决的问题就是在插入的时候不需要那么多的旋转
但如果数据量特别大时,用红黑树的话深度就会变得很多,查找次数就会变多,io效率就会变得很慢
B树堂堂登场——
注意刚才介绍的所有树都是二叉树,而满足下列要求的m叉树就可以被称为B树:
1.树中的每个结点至多有m个孩子结点(至多有m-1个关键字)
2.每个结点的结构为:
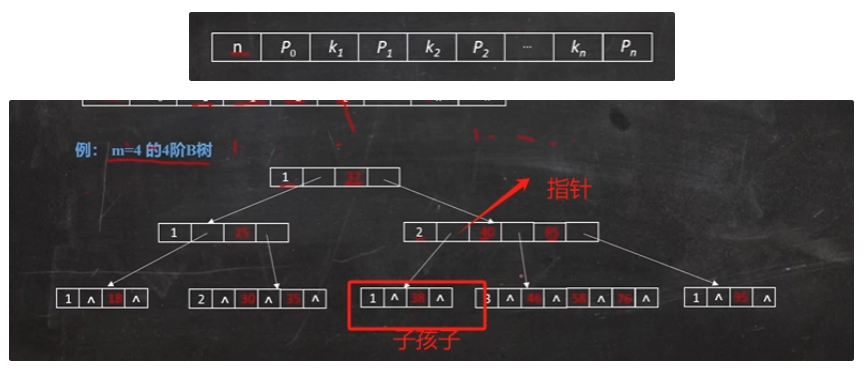
3.除根节点外,其他结点至少有m/2个孩子节点
4.如果根结点不是叶子结点,则根结点至少有两个孩子结点
5.所有叶子结点都在同一层上,也就是B树时所有结点的平衡因子均等于0的多路查找树
那么B树是具体如何实现查找的呢?
B树的查找
在了解b树的查找前,我们应该学会一个预备知识:
磁盘预读:
当内存和磁盘发生数据交互时,一般情况下有一个最小的逻辑单元:页(datapage)
页一般是由操作系统决定时多大的,一般是4k或者8k,在数据交互时,可以取页的整数倍来进行读取。
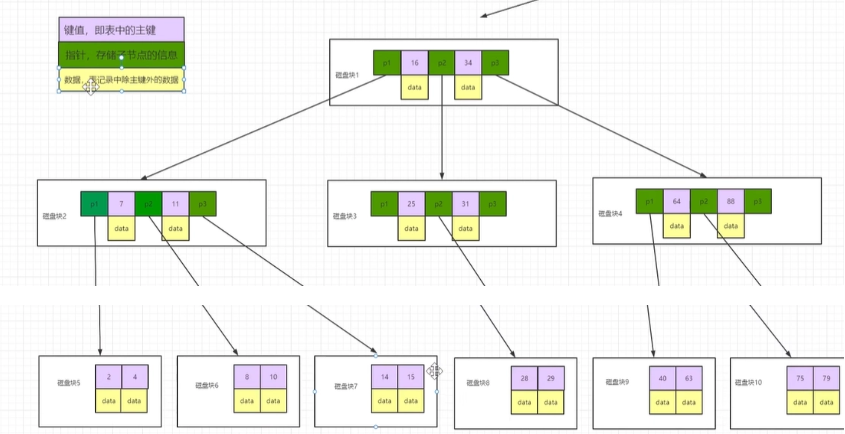
b树的每一个节点都是放在磁盘块里的(datapage),所以如果规定一个datapage时16k,那每一块都是16k,如果现在要找一个关键字为“28”的数据,那么我们就应该先把保存在磁盘块datapage的数据保存到内存里
然后比较大小,16<28<34,所以定位索引p2(第一次io)
继续比较:21<25(第二次io)
继续:找到了(第三次io)
返回关键字对应的data给内存
所以到这里,我们也可以看出b树与b+树的最本质区别了,b树的数据分散在所有结点,而b+树数据只在叶子节点,内部节点只存索引。现在,相信我们可以很好的回答那个“为什么MySQL使用的是B+树而不是B树“的问题了:
1.首先相比于B树来说,访问更加稳定
2.B+树只有叶子结点存放数据,B树是每个节点都存放数据,在相同的数据量下B树的高度更高,所以查询速率更低
(在业务中,其他字段的大小是远远大于主键大小的,如果B树存储,那么一个page存储的数据量就会大大减少)
(但这也要分实际情况,如果主键是uuid而内容是布尔值,那这时B树可能高度会比B+更低)
3.子节点之间存在指针,进行范围查询的时候返回数据更快
(B+树减少了磁盘访问带来的消耗)
至此,本文结束。



