
MyISAM和Innodb是MySQL的存储引擎。
什么是存储引擎
MySQL 存储引擎是数据库管理系统(DBMS)的一个核心底层组件,专门负责数据的读取、写入、存储和索引管理。
在 MySQL 的架构中,它位于 SQL 接口和文件系统之间,起到“数据处理器”的作用。
想要了解它的具体意思,我们必须从MySQL的架构说起:
MysQL架构:
MySQL采用的是插件式存储引擎架构,他会查询处理与数据存储/提取彻底解耦
它分为:
1.连接层与服务层(Server层):
负责连接管理、查询缓存、SQL解析、预处理、查询优化。
2.存储引擎层(Storage Engine层):
Server层通过一层标准的存储引擎API与下层通信,无论是InnoDB还是MyISAM,server层调用的接口都是一致的。
3.文件系统层(磁盘)
存储引擎最终将数据写到磁盘的物理文件上。
而我们今天所要讲的主角就位于第二层,它负责链接server与磁盘的执行接口;并决定了数据在磁盘的排布形式;并提供了数据库的核心功能特性(事务、并发控制、崩溃恢复)
了解了他们的基本功能和所在位置,我们接下来继续来深入学习。
MyISAM和Innodb的不同
(一)存储结构不同
两种存储引擎在磁盘上的存储形式不同。
1.MyISAM会存储
.frm文件(表结构文件)
.MYD文件(数据文件)
.MYI文件(存储索引文件)
2.InnoDB则会存储为:
.frm文件(表结构文件)
.idb文件(存储数据和索引文件)
先说MYI,在前文我们了解了B树和B+树,了解了数据库存储文件的原理和存储引擎的所在位置
相互联系一下,不难发现索引会存储在MYISAM中的MYI文件中;数据则会存储在MYD文件中
举个例子,假设索引列是col1,我们写一条查询语句:
select * from t where col1=30我们来从头捋一下它的执行逻辑:
mysql首先会去看where后面的字段是不是索引字段,
如果是索引字段, 它会先拿着索引的值去MYI文件里从根结点开始遍历查找这个元素(具体请看上一篇B+tree)
拿到叶子结点内存储的文件磁盘地址(因为MyISAM的索引和数据是分开存储的,所以myisam的叶子节点存储的是数据所在的地址,而不是数据)
拿到这个地址后,会带着它来到MYD文件,用这个地址去定位整行记录的位置把整行记录全部拿出来
再说innodb
唯一的不同其实就是叶子结点存储的不是地址而是索引列所在行其他所有列的结果,而这就是聚集索引
MYSI则是非聚集索引,一位内索引和数据是分开来存储的
值得注意的是,Innodb的主键索引和非主键索引的存储方式亦有不同;
innodb的主键索引存储方式是B+树,而非主键索引的存储结构是叶子结点放主键索引的主键,如下图的例子,如果要找Jim,通过一段比大小后,找到的是主键的主键字段值,再回到idb文件里去找到对应的表内容
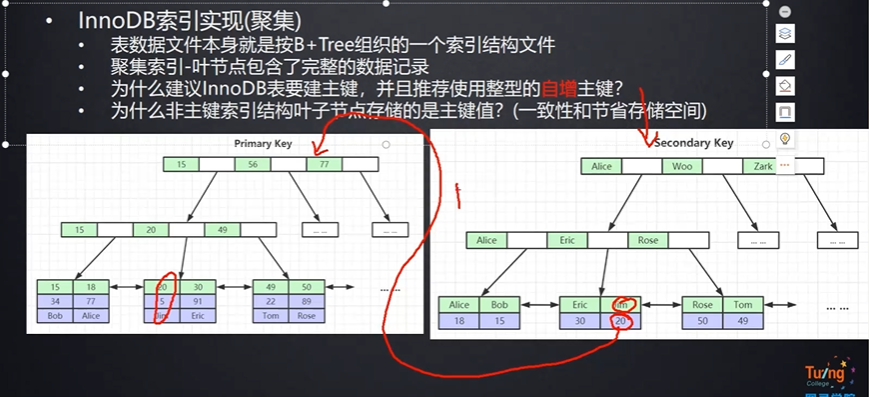
这个过程也叫回表,所以如果用主键查,效率会很高;所以一般用innodb一定要建主键,而且不要用uuid,不然字节占太长了()
如果你没有建唯一索引,innodb会自动建造一个rowid用来维护这个b+树,那肯定是要能自己建就自己建,这个rowid只是为了防止逻辑崩塌而存在的隐藏字段( 是不能根据rowid去查找数据的

而关于主键id,有很多种思路可以去命名,比如很众所周知的雪花算法:
Innodb的主键id
雪花算法
如果我们希望id可以按照时间有序生成时就可以使用雪花算法来解决这个问题
1.原理
可以理解为一台拥有独立编号的服务器在毫米级时间戳内生成带有子帧序号的id
生成的是64比特结构的序号

41bit可以使用69年
10bit代表可以部署在1024台服务器上
后12bit可以表示同一毫秒内生成的第几个id,可以表示为4096个数字,所以雪花算法在一毫秒内最多可以生成4096个数字
由于生成的id带有时间戳,所以生成的id实际上是跟着时间递增的
2.雪花算法的实现
时间戳:now
机械编号id:workID
序列号:n
now = time() #获取当前毫秒时间戳
if now == last: #用当前获取的毫秒时间戳作比较,如果相同,就说明是在同一毫秒生成的时间戳
n +=1
if n > 4096:
now = nexttime()
n=0
else:
n=0
last=now
ID = now <<22 | workID << 22 | n #左移22位但其实如果在分库分单的时候用雪花算法其实不太方便的,因为雪花算法是自增主键类型
虽然雪花算法解决了全局唯一性的问题,但在分库分表时,它有几个天然的“别扭”点:
雪花算法的核心是时间戳。这意味着在同一时间段内生成的 ID,其高位比特位是非常接近的。
如果你直接对 ID 进行取模(ID % 分库数量),由于 ID 是递增的,连续生成的 ID 会均匀分布。但是,如果你使用的是范围分片(Range Sharding,例如 1-100万在一个库,101-200万在一个库),那么短时间内所有的写操作都会堆积在同一个最新的分库/分表中,导致该节点压力过大,无法发挥分布式集群的并发优势。
雪花 ID 通常是 64 位的 Long 类型。相比于传统的 32 位自增 Int,它占用的存储空间翻倍。在 MySQL 的 B+ Tree 索引结构中,非叶子节点能存储的记录行数会减少,从而可能增加树的高度,增加磁盘 I/O 次数。
雪花算法是趋势递增,而不是绝对连续自增。在某些业务逻辑中,如果严格依赖 ID 的连续性(比如判断某一天处理了多少单),雪花算法中间会有“空洞”(因为毫秒跳变或机器位不同),这会让某些老旧的统计逻辑感到不适
但是在微服务架构中,雪花算法会被广泛应用,因为不同服务(订单、支付、物流)产生的记录需要一个全系统唯一的标识。
这就引出了一个更广阔的架构命题:分布式 ID 系统的设计。 雪花算法只是实现分布式 ID 的一种路径,为了克服它的局限性,业界还演化出了如号段模式、Redis 计数器等多种成熟的分布式 ID 方案。”
我们先讲分布式id:
雪花算法的分布式ID
要了解雪花算法的分布式ID,我们必须清楚分布式id和常见的分布算法都有哪些
要了解分布式id,我们首先要学习一个前置条件
什么是UUID?
UUID 的全称是 Universally Unique Identifier(通用唯一识别码)。
简单来说,它的设计目标是让分布式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端(如主数据库)来指定 ID
目前最常见的版本是UUID V4,是基于128位纯随机数生成的id,理论上,只要随机数生成器足够“随机”,两个id撞车的概率基本为0,但其实,它的隐患非常大。
但正如我们的随机上打的引号,计算机实际上是无法真正的随机的,它们只能产生伪随机。
计算机的本质是由逻辑门电路组成的,对于给定的输入和给定的个算法,它必须产生确定的、可预测的输出。而伪随机数生成器(RPNG)本质上是一个数学公式,只要你给它一个起始数字(即种子Seed),他就能通过复杂的运算,产生一串看起来乱七八糟、毫无规律的数字序列。
但是——如果sedd相同,那么计算机生成的这个数字序列也就会完全相同(就是生成的随机数一样)
所以,回到我们现在的聊的话题,为什么uuid的隐患很大,以java为例,当你写new Random()时,它的内部源码其实干了这件事:
“既然用户没给我种子,我就偷偷去拿一下系统当前的时间(纳秒级)作为种子。”
所以,种子其实是由环境(JRE/Python解释器)自动提供的,它通常来源于:
1.系统时钟(最常见的来源)
2.进程id
3.原子变量自增
所以,当在分布式、高并发的服务器上,多个请求几乎在同一微秒到达,它们初始化的 Random 对象极易拿到相同的种子,如果涉及到订单之类的数据库主键命名,灾难程度将会无法想象。
反观雪花算法,尽管也是以时间戳为基础,但规定了一毫秒最多只能生成4096个数字,根本无法相同。
了解了uuid,接下来我们可以了解分布式id了:
什么是分布式ID?
简单来说,分布式 ID 是在物理上分散、逻辑上统一的系统中,为每一条数据生成的全局唯一标识。
想象一下,你正在为学校开发一个抢课系统,因为学生太多,你部署了 2 台服务器和 2 个对应的数据库:
如果两个数据库都从 1 开始自增,那么两台机器都会产生 ID=1 的记录。当你试图把两张表的数据合并做报表时,主键就撞车了。
如果两个数据库都从 1 开始自增,那么两台机器都会产生 ID=1 的记录。当你试图把两张表的数据合并做报表时,主键就撞车了。
而解决这种问题的方法也有很多,比如刚才我们讲到的雪花算法
这里我们提一嘴,在追求极致性能的数据库服务中,如果我们不用雪花算法,也不用 UUID,那么就用整数型去处理就好了。
关于主键要递增,我们这里还要介绍一种索引方法
Hash
hash的结构其实就是:
一个一维的数组 加上 一个二维的链表 来存储的
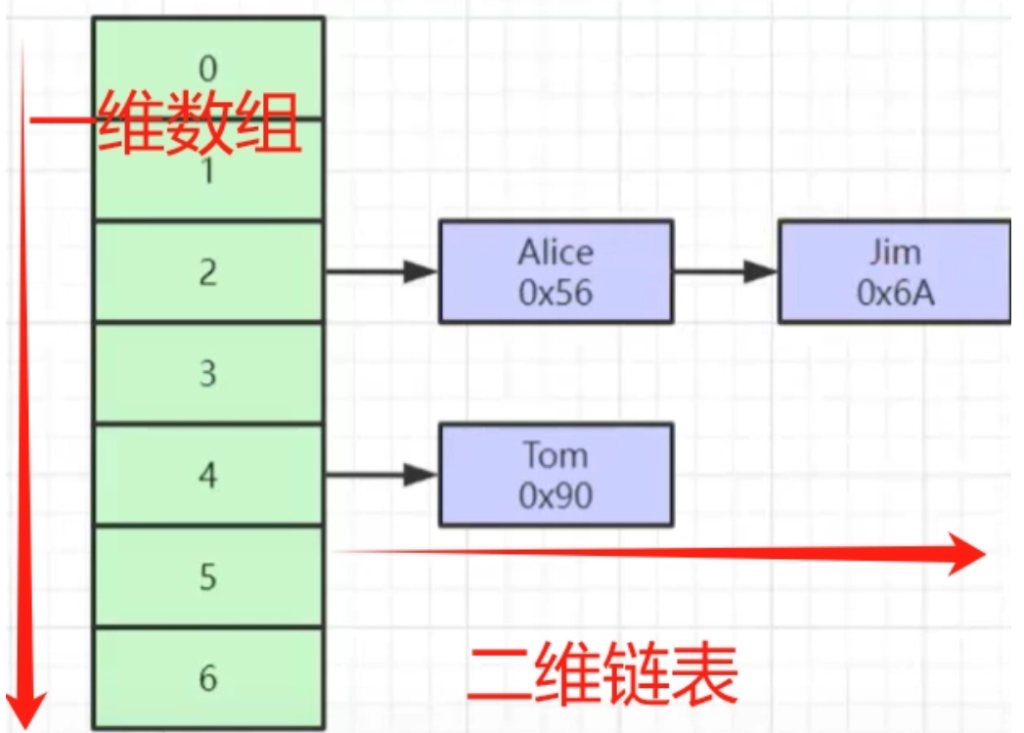
那是怎么存的呢?
其实就是对这个哈希字段做一个哈希闪列运算,再对长度取一个模 举个例子,我现在有一个col3,里面存储了“Alice”“Jim”“Tom”
那对他们进行哈希就是这样的

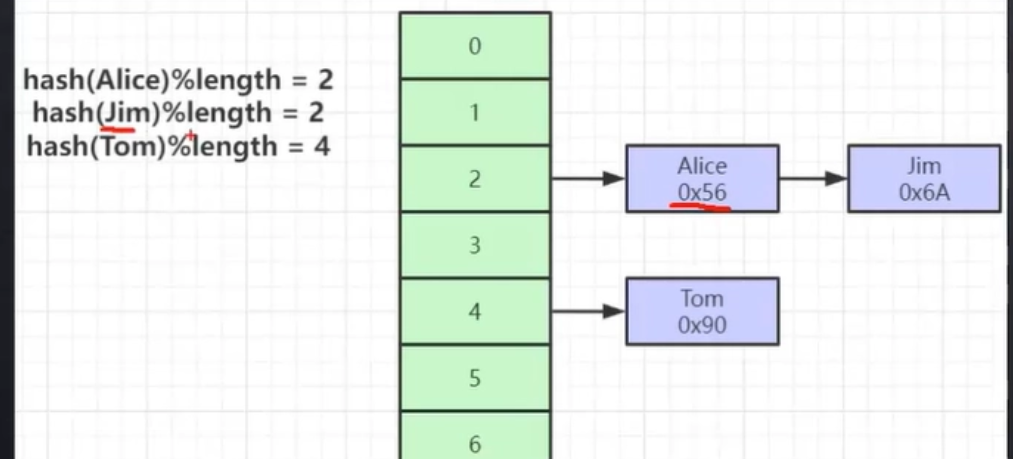
哈希查找效率相当高,比B树还要高,但其实生活中很少用到,就是因为它太浪费内存了
哈希查找是不支持范围查找的,其实核心原因就四个字:“无序性”,B+ Tree 索引中,叶子节点是排好序的,你找到 $10$ 之后,顺着链表往后“滑”就能找到后面的数据。但在哈希表里,数据是乱序散落在各个桶里的。
要找这个范围,哈希索引唯一能做的就是把所有的桶全部打开看一遍,确认哪些落在 $10-20$ 之间。这已经失去了“索引”的加速意义,变成了全表扫描
我们对之前的B+tree做一个补充说明,叶结点之间互相是有一个双向指针的,所以当我们找到了一个元素,其实是可以跟着这个双向指针,一路顺下去的
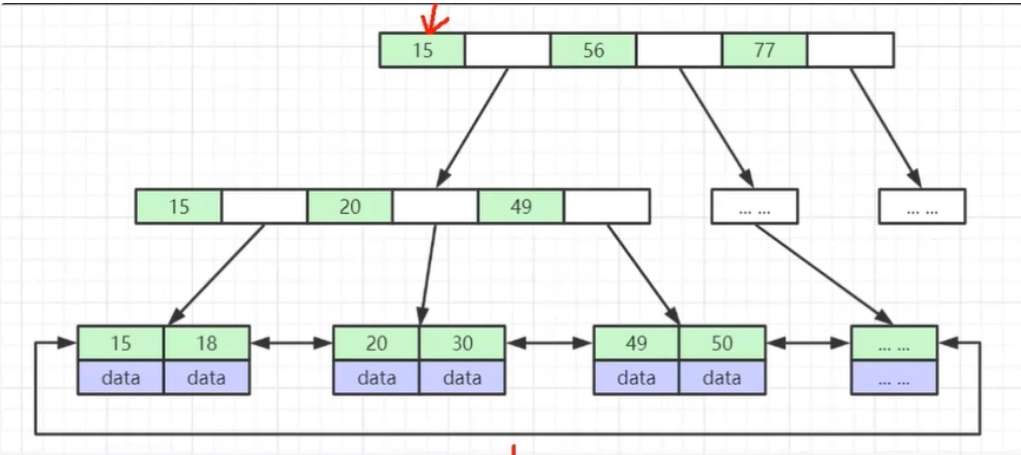
这其实也是B+和B的又一不同,因为B结点之间是没有双向指针的,也就是也没办法范围查找的
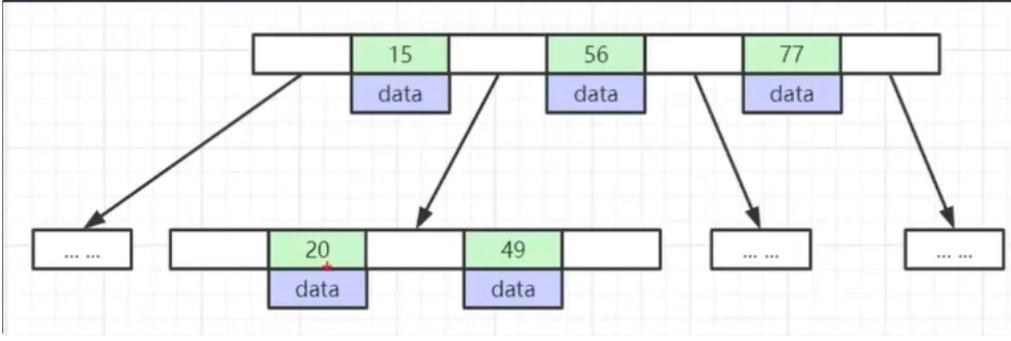
回到我们刚刚说的,为什么推荐自增(uuid就不是自增),就是因为我们可以根据双向指针去范围查询。

到这里,讲了很多扩展知识,MyISAM和InnoDB就算讲完了。



